Construisons l'avenir
Tech du Bénin ensemble
Rejoignez la plus grande communauté de développeurs au Bénin. Apprenez, partagez vos connaissances et collaborez sur des projets open source innovants.
Notre Mission :
Connecter, Former, Propulser
DevBénin est le catalyseur de l'écosystème tech béninois. Nous créons un environnement propice à l'innovation, à l'apprentissage et à la collaboration professionnelle.
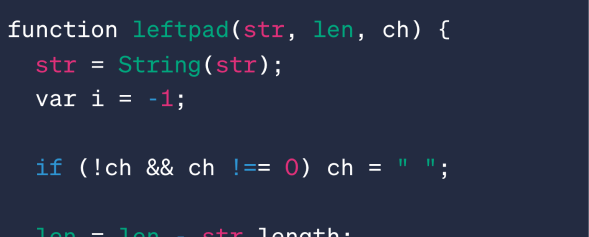
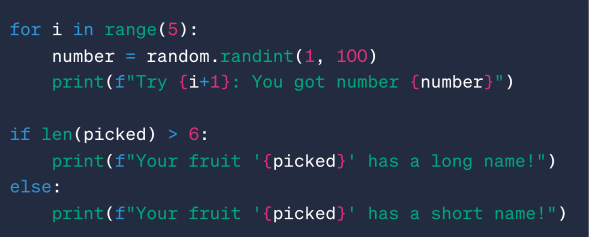
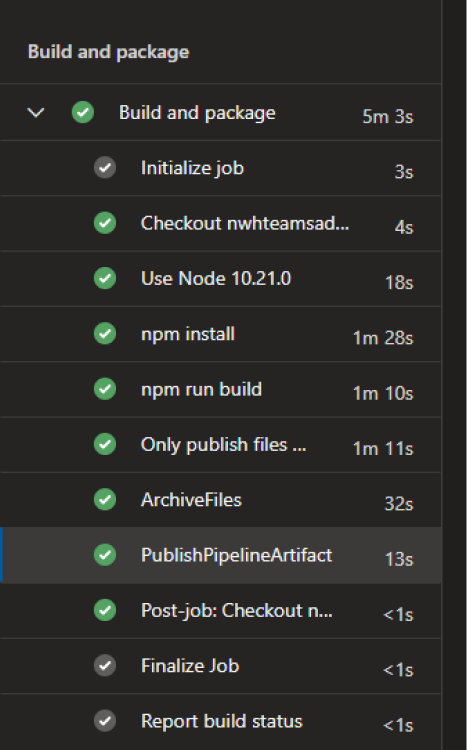
Le Coin Blog
Un espace dédié à l'innovation, l'apprentissage et le partage de connaissances qui font la différence dans l'écosystème tech béninois.
Voir tous les articlesProjets de la communauté
Découvrez les dernières créations des développeurs du Bénin. Open source, startups et expérimentations.
Quiz récents
Des QCM courts pour vérifier ce que tu maîtrises. Gagne des points et grimpe dans le classement.
DevSearch
Une question, une réponse claire - directement issue de la documentation officielle de tes frameworks préférés.
Top Talents & Mentors
Rencontrez les développeurs expérimentés et mentors qui façonnent l'avenir de la tech au Bénin.
Prêt à transformer votre carrière ?
Rejoignez la communauté des développeurs béninois. Partagez vos projets, apprenez des meilleurs experts et développez votre réseau professionnel dès aujourd'hui.